
We address the task of domain adaptation in object detection, where there is an obvious domain gap between a domain with annotations (source) and a domain of interest without annotations (target). As a popular semi-supervised learning method, the teacher-student framework (a student model is supervised by the pseudo labels from a teacher model) has also yielded a large accuracy gain in cross-domain object detection. However, it suffers from the domain shift and generates many low-quality pseudo labels (e.g., false positives), which leads to sub-optimal performance. To mitigate this problem, we propose a teacher-student framework named Adaptive Teacher (AT) which leverages domain adversarial learning and weak-strong data augmentation to address the domain gap. We show that AT demonstrates superiority over existing approaches and even Oracle (fully-supervised) models by a large margin. For example, we achieve 50.9% (49.3%) mAP on Foggy Cityscape (Cli- part1K), which is 9.2% (5.2%) and 8.2% (11.0%) higher than previous state-of-the-art and Oracle, respectively.
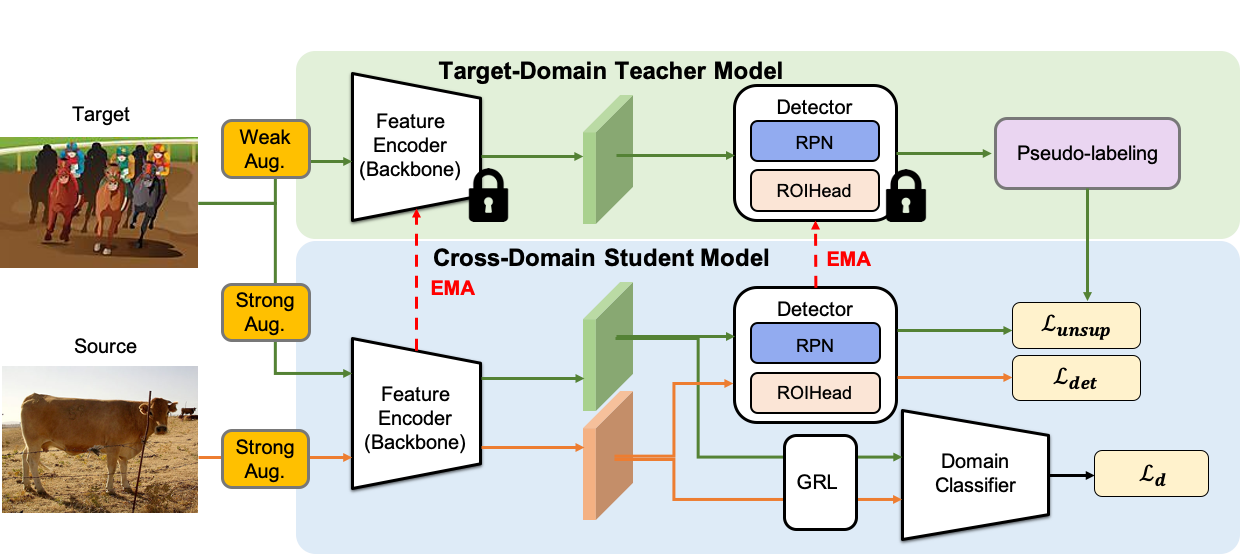
Our model consists of two modules: 1) target-specific Teacher model for taking weakly-augmented images from target domain and 2) cross-domain Student model for taking strongly-augmented images from both domains. We train our model using two learning streams: Teacher-Student mutual learning and adversarial learning. The Teacher model generates pseudo-labels to train the Student while the Student updates the Teacher model with exponential moving average (EMA). The discriminator with gradient reverse layer is employed to align the distributions across two domains in Student model.

@inproceedings{li2022cross,
title={Cross-Domain Adaptive Teacher for Object Detection},
author={Li, Yu-Jhe and Dai, Xiaoliang and Ma, Chih-Yao and Liu, Yen-Cheng and Chen, Kan and Wu, Bichen and He, Zijian and Kitani, Kris and Vajda, Peter},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
This project is done partially while Yu-Jhe Li was interning at Meta (Facebook).